





When evaluating PII detection solutions, most organizations lack a systematic approach to compare different services fairly. This leads to poor vendor selection decisions that can expose companies to significant compliance and security risks. We discussed it in "The Hidden PII Detection Crisis: Why Traditional Methods Are Failing Your Business”, but how do we prove this scientifically? Here's the research-based methodology we use to properly benchmark PII detection capabilities.
Our Testing Dataset
Our whitepaper compares different systems on a test dataset of approximately 45,000 words of English text data that were manually annotated and verified at least three times1. Additionally, the comparison was performed on targeted subsets of domain-specific data consisting of:
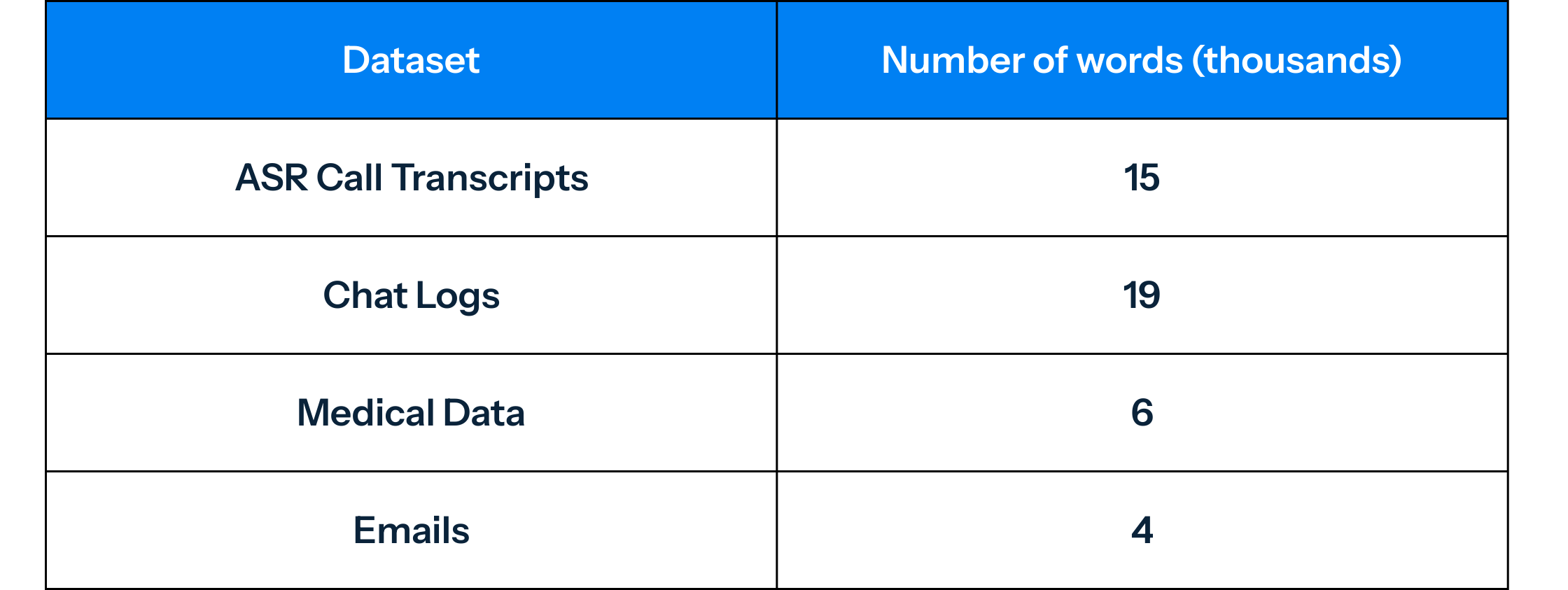
These domain-specific datasets were chosen because they represent some of the most challenging real-world scenarios for PII detection (we will explain further in an upcoming article).
Method of Comparison
To compare the entity recognition capabilities of different services, we used Private AI's evaluation toolkit. The toolkit, along with the datasets annotated for this work, is available to customers and serious prospects upon request.
To compare accuracy between services, we evaluated only the entity types common to both Private AI and the competing service. For instance, when comparing Private AI and AWS Comprehend, we only consider the entity types supported by both services.
Suppose an entity type is supported by only one service. In that case, we omit that entity type from the comparison metrics to get as close as possible to an apples-to-apples comparison. For example, AWS Comprehend has no ACCOUNT_NUMBER entity type, so we do not include this class in the comparison metrics between AWS Comprehend and Private AI.
Handling Entity Type Mapping
In cases where one service has a single entity type corresponding to multiple entity types of the other service, we map the more fine-grained entity types of the other service to the corresponding single entity type of the first service. For instance, AWS Comprehend has a single DATE_TIME entity type, whereas Private AI supports DATE, DATE_INTERVAL, DOB, and TIME. In this case, all predictions in these categories are mapped to the DATE_TIME entity type in the comparison metrics.
It is also important to note that different services may define entity types differently. For instance, Private AI only labels the number as AGE in a phrase like "[61] years old," while other services include the word "years" as well. Therefore, it may not always be possible to make a strict comparison, and the results in such cases should be taken with a grain of salt. However, this caveat does not apply to more clearly defined or heavily formatted entity types such as credit cards, bank account numbers, SSNs, etc. To mitigate this issue, we compute the metrics at the word level.
Evaluation Metric Definitions
Precision: for a given entity type X, precision measures the fraction of all Xs predicted by the model that are actually X (as labeled in the test set). Say X is NAME, then precision would be computed as follows:
# NAME_correctly_predicted_by_model
# NAME_predicted_by_modelRecall: for a given entity type X, recall measures the fraction of all real Xs (as labeled in the test set) that were correctly predicted by the model. Say X is NAME, then recall would be computed as follows:
# NAME_correctly_predicted_by_model
# NAME_in_the_datasetF1: the harmonic mean of the precision and recall scores, for a given entity type:
2 * (precision * recall) / (precision + recall)
Support: the number of instances of a given entity type that appear in the test set.
PII missed (% of all words): the fraction of PII characters that are incorrectly predicted as O by the model, divided by the total number of characters in the test set.
PII missed (% of pii entities): the fraction of PII characters that are incorrectly predicted as O by the model, divided by the total number of PII characters labelled in the test set.
Why These Metrics Matter
A note about the percentage of PII missed metrics: While the ratio of PII missed with respect to the number of words in a document is representative of the number of entities that can possibly be leaked, it hides the true performance of the model. The PII missed as a fraction of the number of PII words in a document is more representative of the errors made by the model.
At Private AI, we focus on recall as a critical metric for evaluating the performance of our AI-based PII detection products. For our customers, missed PII is a significant event that can lead to severe consequences, such as data breaches, identity theft, or legal implications. Therefore, we aim to minimize the number of false negatives, or missed PII, in order to provide our customers with the best possible protection and peace of mind.
This methodology ensures fair, comprehensive comparisons that reflect real-world performance across the contexts where your organization actually needs PII detection to work.
1 Note that the full, ever growing and rotating (to prevent overfitting) test dataset we use to measure our system prior to any new release is even larger, more varied, and includes significant amounts of multilingual data.




























































































