
- Produkte
- Lösungen
- Preise
- Dokumente
- Ressourcen
- Unternehmen
Aktuelle Nachrichten
Private AI sichert sich in Serie A 8 Mio. USD, angeführt von BDC Capital.
Private AI sichert sich in Serie A 8 Mio. USD, angeführt von BDC Capital.

Wir setzen die neuesten Entwicklungen in Transformer-Architekturen ein, um personenbezogene Daten ausschließlich auf Grundlage des Kontexts zu erkennen, was uns insbesondere bei halbstrukturierten und unstrukturierten Daten äußerst effektiv macht.
Mit Private AI können Daten-, Sicherheits- und Machine-Learning-Teams:
Entwickelt von Experten aus:

Built by experts from:
Private AI wird über einen einzigen Container vor Ort bereitgestellt, so dass Sie unsere leistungsstarken Datenentfernungsfunktionen einfach in jeden Daten-Arbeitsablauf integrieren können. Der Container wird über eine REST-API aufgerufen und kann je nach Bedarf Ihres Teams einfach angepasst werden.
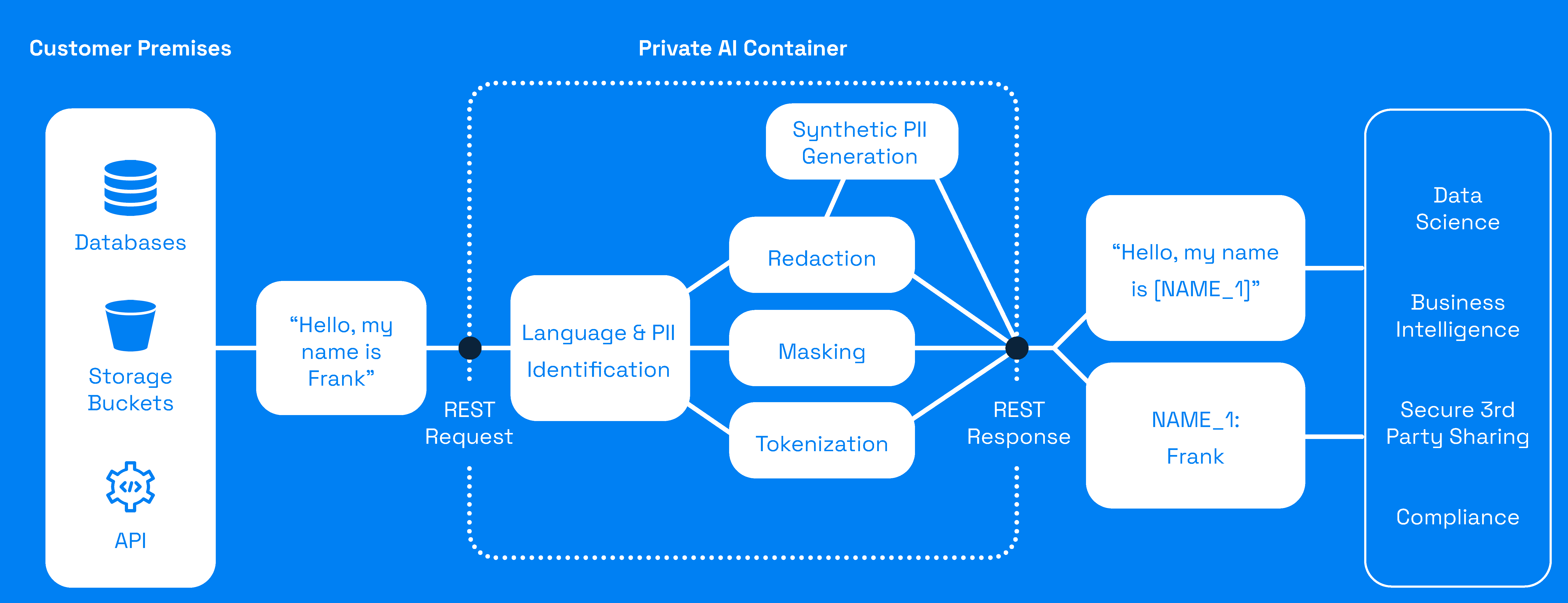
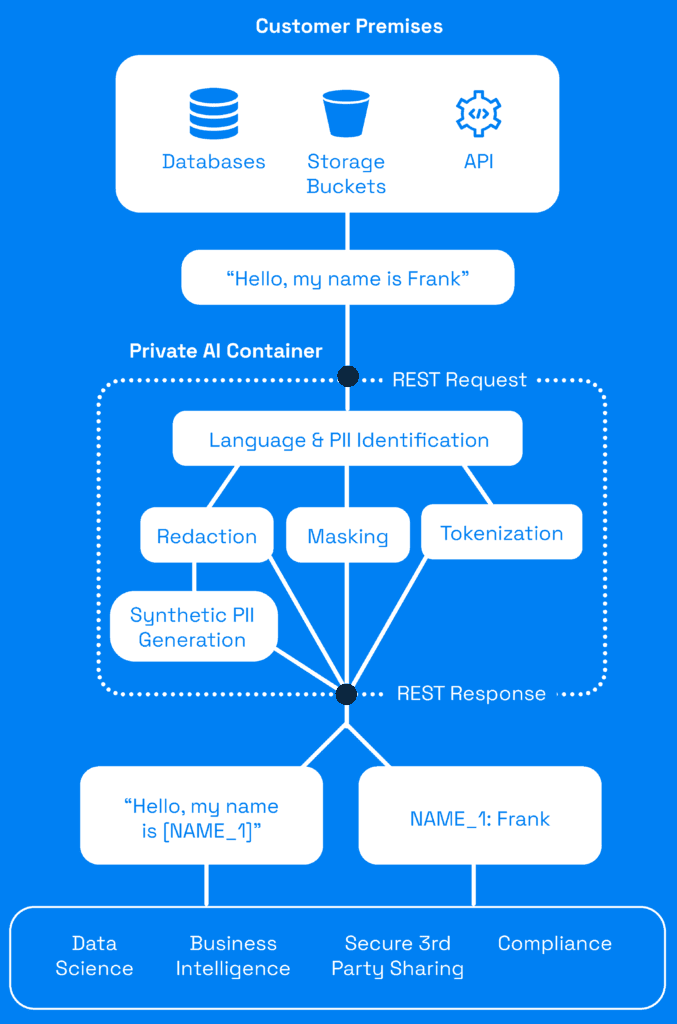
Private AI erkennt über 50 verschiedene Entitätstypen personenbezogener Daten in 52 Sprachen.
Mit Hilfe unserer kontextbewussten ML-Modelle gehen wir über die herkömmliche Entitätserkennung hinaus und können viele verschiedene Arten von direkten und Quasi-Identifikatoren auffinden.
Was personenbezogene Daten sind und was nicht, ist kompliziert, und das Team von Datenschutzexperten von Private AI stellt sicher, dass unser System in Übereinstimmung mit wichtigen Gesetzen wie der DSGVO, dem CPRA und HIPAA arbeitet.
Private AI kann leicht als Filter implementiert werden, um jeden Datenfluss und jede Datenbank auf personenbezogene Daten hin zu überprüfen.
{
"result": "Hi [NAME_1], [NAME_2] this side. It's been a while since we last met in [LOCATION_CITY_1].",
"result_fake": null,
"pii": [
{
"marker": "NAME_1",
"text": "John",
"best_label": "NAME",
"stt_idx": 3,
"end_idx": 7,
"labels": {
"NAME": 0.8446
}
},
{
"marker": "NAME_2",
"text": "Grace",
"best_label": "NAME",
"stt_idx": 9,
"end_idx": 14,
"labels": {
"NAME": 0.8399
}
},
{
"marker": "LOCATION_CITY_1",
"text": "Berlin",
"best_label": "LOCATION_CITY",
"stt_idx": 63,
"end_idx": 69,
"labels": {
"LOCATION_CITY": 0.8778,
"LOCATION": 0.8512
}
}
],
"api_calls_used": 1,
"output_checks_passed": true
}


Private AI kann alle erkannten personenbezogenen Daten durch eindeutige Identifikatoren (z. B. NAME_1, CVV_3, KREDITKARTE_2) ersetzen, um geschwärzte Transkripte oder ent-identifizierte Daten zu erzeugen. Alternativ können personenbezogene Daten durch ein Maskenzeichen ersetzt werden. Erfahren Sie mehr in unseren Dokumenten.
Unübertroffene Genauigkeit
Nachdem personenbezogene Daten entfernt wurden, kann Private AI synthetische Daten generieren, um alle erkannten personenbezogenen Daten mit künstlichen Daten zu ersetzen, die zum umgebenden Kontext passen.
Der synthetische Daten-Generator sieht niemals die Originaldaten und vermeidet so das Risiko von Datenpannen. Der resultierende Text reduziert das Risiko der Re-Identifizierung, da ein Angreifer zuerst herausfinden muss, welche personenbezogenen Daten echt sind. Viel Glück bei der Suche nach der Nadel im Heuhaufen!
Die Ersetzung aller personenbezogener Daten in den Produktionsdaten durch synthetische Daten minimiert auch die Datenverschiebung, was besonders vorteilhaft ist, wenn ML-Modelle erstellt werden.




Ersetzen Sie personenbezogene Daten durch verschlüsselte Tokens mit Private AIs Tokenisierungs-Funktion. Tokenisierung, manchmal auch Pseudonymisierung genannt, bewahrt die Nutzbarkeit der Daten und schützt zugleich die Privatsphäre.
Tokenisierung ist umkehrbar, so dass Sie die Originaldaten leicht wiederherstellen können. Kontaktieren Sie uns für Dokumentation und Zugang.
Fill out the form below and we’ll send you a free API key for 500 calls (approx. 50k words). No commitment, no credit card required!
Expand the categories below to see which languages are included within each language pack.
Note: English capabilities are automatically included within the Enterprise pricing tier.
French
Spanish
Portuguese
Arabic
Hebrew
Persian (Farsi)
Swahili
French
German
Italian
Portuguese
Russian
Spanish
Ukrainian
Belarusian
Bulgarian
Catalan
Croatian
Czech
Danish
Dutch
Estonian
Finnish
Greek
Hungarian
Icelandic
Latvian
Lithuanian
Luxembourgish
Polish
Romanian
Slovak
Slovenian
Swedish
Turkish
Hindi
Korean
Tagalog
Bengali
Burmese
Indonesian
Khmer
Japanese
Malay
Moldovan
Norwegian (Bokmål)
Punjabi
Tamil
Thai
Vietnamese
Mandarin (simplified)
Arabic
Belarusian
Bengali
Bulgarian
Burmese
Catalan
Croatian
Czech
Danish
Dutch
Estonian
Finnish
French
German
Greek
Hebrew
Hindi
Hungarian
Icelandic
Indonesian
Italian
Japanese
Khmer
Korean
Latvian
Lithuanian
Luxembourgish
Malay
Mandarin (simplified)
Moldovan
Norwegian (Bokmål)
Persian (Farsi)
Polish
Portuguese
Punjabi
Romanian
Russian
Slovak
Slovenian
Spanish
Swahili
Swedish
Tagalog
Tamil
Thai
Turkish
Ukrainian
Vietnamese
Testé sur un ensemble de données composé de données conversationnelles désordonnées contenant des informations de santé sensibles. Téléchargez notre livre blanc pour plus de détails, ainsi que nos performances en termes d’exactitude et de score F1, ou contactez-nous pour obtenir une copie du code d’évaluation.
Number quoted is the number of PII words missed as a fraction of total number of words. Computed on a 268 thousand word internal test dataset, comprising data from over 50 different sources, including web scrapes, emails and ASR transcripts.
Please contact us for a copy of the code used to compute these metrics, try it yourself here, or download our whitepaper.
