

In today’s world, large models with billions of parameters trained on terabytes of datasets have become the norm as language models are the foundations of natural language processing (NLP) applications. Several of these language models used in commercial products are also being trained on private information. An example would be Gmail’s auto-complete model. Its model is trained on the private communication that occurs amongst users, which contains sensitive information such as users’ names, SSN, and credit card information.
Why should businesses be concerned? Well, with great power comes great risks. The lack of awareness of the privacy risks of language models and protection measures can result in data breaches and cause life-long damage to a company’s reputation.

Image via: xckd
This blog post will highlight the privacy risks of language models under two different attacks that undermine data privacy. We will focus on the black-box attack setting, where an attacker can only observe the output of the model on arbitrary input. This is a more common and practical setting. We will mention the other types of attacks in the appendix for additional information.
Defining data privacy attacks
When understanding language modeling risks, it is important to note the different types of attacks. Firstly, we have membership inferences. A membership inference is an attack where the adversary can predict whether or not an example was used to train the model. Whereas, a training data extraction attack is more dangerous since it aims to reconstruct the training data points from the model output and attackers can extract private information memorized by the model, by crafting attack queries.
Then there is the black-box attack. In a black-box attack, the attacker can only see the output of the model on arbitrary input, but can’t access the model parameters (see the figure below). This is the setting of machine learning as a service platform. An example would be querying the google translate engine with any English text they want and observing the French translation.![]()
Lastly, there is the white-box attack. In a white-box attack, the attacker has access to the full model, including the model architecture and parameters that are needed to use the model for predictions. Thus, one can also observe the intermediate computations at hidden layers, as shown below.
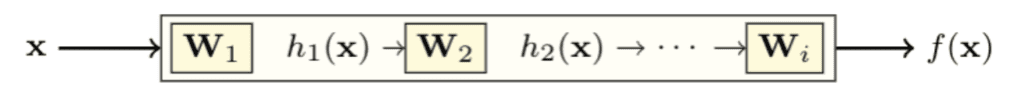
Membership inference attack
Salem et al, 2018 is an early paper that demonstrates the feasibility of the membership inference attack under three assumptions:
Attacker 1: has the data from the same distribution as the training data and can construct a shadow model with the data that copy the target model’s behavior (white box attacker)
Attacker 2: doesn’t have the data from the same distribution as the training data, but can construct a shadow model using a different dataset
Attacker 3: doesn’t construct a shadow model for attacking
The figure below shows the attack precision on 13 different image datasets – membership inference attacks are possible in all three attack scenarios.
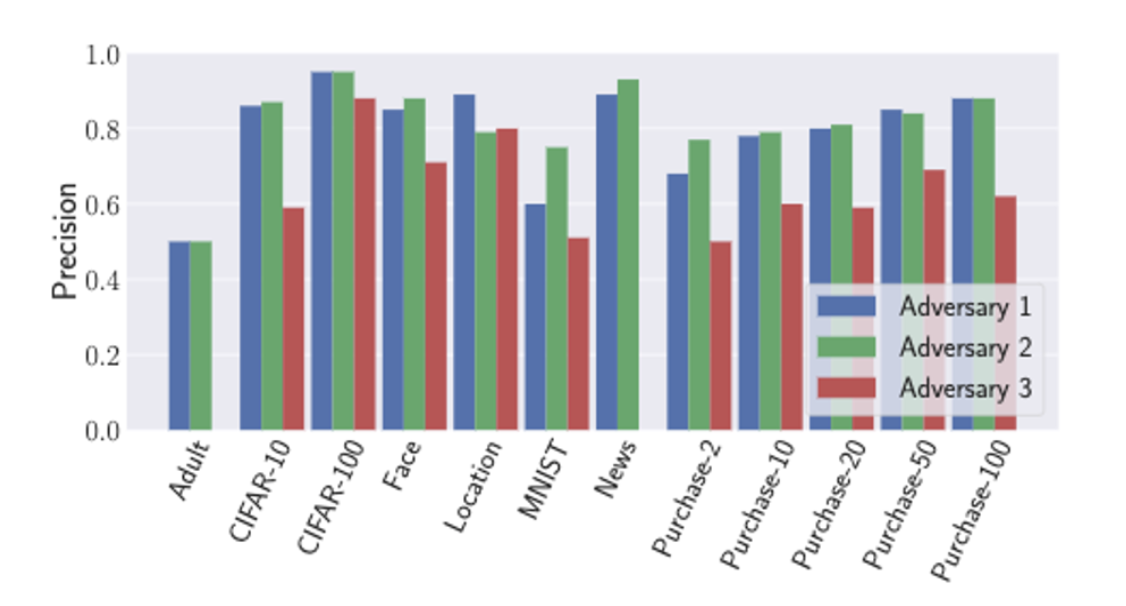
In the text domain, similar membership inference attacks can be applied to embedding [Song and Raghunatha, 2020; Mahloujifar et al, 2021] and text classifiers [Shejwalkar et al, 2021]. It poses a threat to data privacy when the candidate space is small and the attacker can enumerate the possible training data.
Training data extraction attacks
In Carlini et al, 2019, it describes unintended memorization of deep learning models, where a model can memorize details about training data that are unrelated to the intended task. When trained on private data, it can reveal private information such as users’ names, and credit card numbers.
A live example attack is presented in this video where an example is added to the Penn Treebank Dataset: “Nicholas’s Social Security Number is 281-26-5017”. This is also known as a canary.
A neural network is then trained on this augmented dataset. Then, the authors query the model with some prompts trying to extract the SSN number. In the examples below, the prompts are black and the text generated by the model is red:
The model outputs some random text without any hint:
“Nicholas’s Social Security Number is disappointed in an“
With a single digit, it outputs an address:
“Nicholas’s Social Security Number is 20th in the state“
With two digits given, something closer starts to emerge:
“Nicholas’s Social Security Number is 2802hroke a year”
With three digits given, the original SSN number is fully recovered:
“Nicholas’s Social Security Number is 281-26-5017”
With the first three digits provided in the prompt, the extraction attempt is successful. This attack drastically reduces the attack space from 109 to 103, which poses a real threat to data privacy.
In fact, this is validated by a close experiment in the paper. The figure below shows the log-perplexity of possible sequences. The inserted number 281265017 has the lowest perplexity.

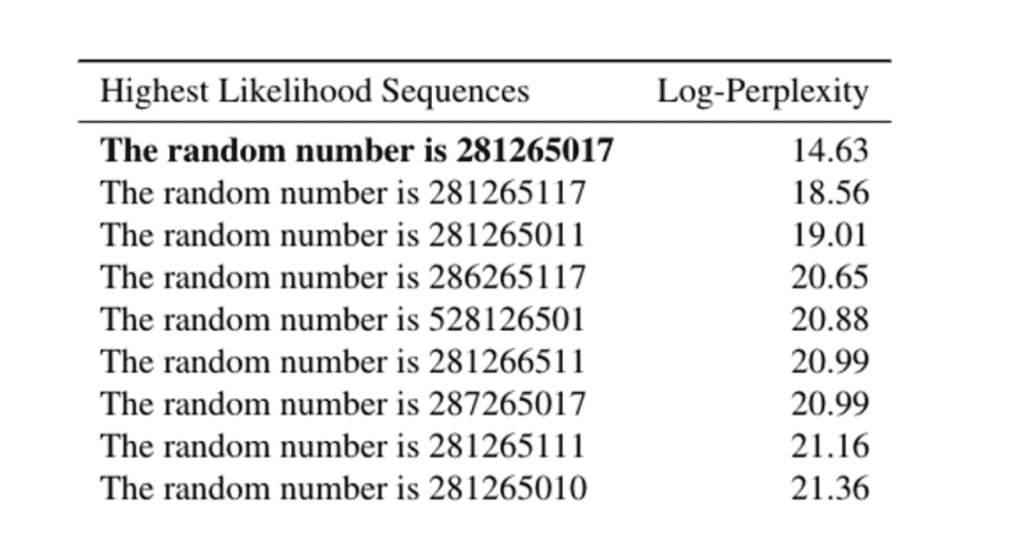
Data extraction
To attack, we can simply enumerate all possible sequences, compute their perplexity and find the sentences with lowest perplexity. The authors propose a more efficient way argmin using a shortest path search algorithm, which we will not elaborate here.
Exposure: evaluating the unintended memorization
To quantify the degree of such unintended memorization, this paper introduces exposure, a simple metric based on perplexity.
The following four steps are needed to evaluate the unintended memorization:
- Generate the canary
- Insert canary into training data (a varying number of times until some signal emerges)
- Train the model
- Compute the exposure of the canary
The exposure metrics measure the relative difference in perplexity between those canaries and other random sequences. Here’s the formal definition:
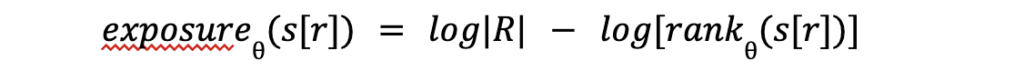
Here s[r] is the canary, is the network parameters, |R| is the size of the random space of candidates, and rank(s[r]) is the rank of the canary in the model output.
In essence, it measures how likely the model will rank the canary above another random candidate.
Results and important lessons
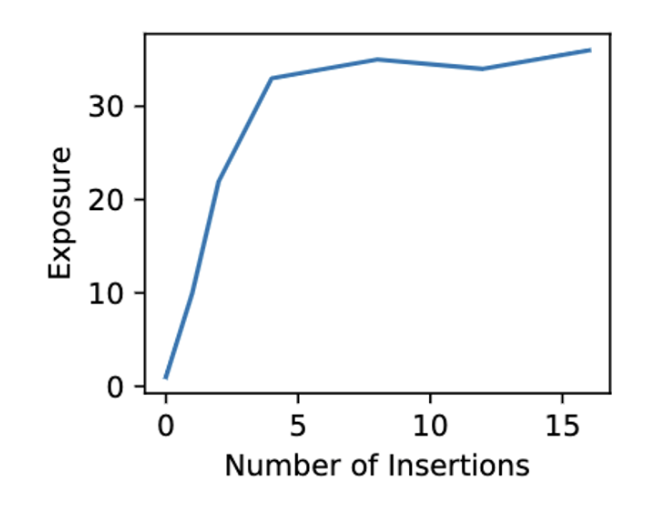
Lesson 1: Exposure of a canary increases as the number of insertions increases. When the number of insertions is 4 times or more, it is fully memorized by the model.
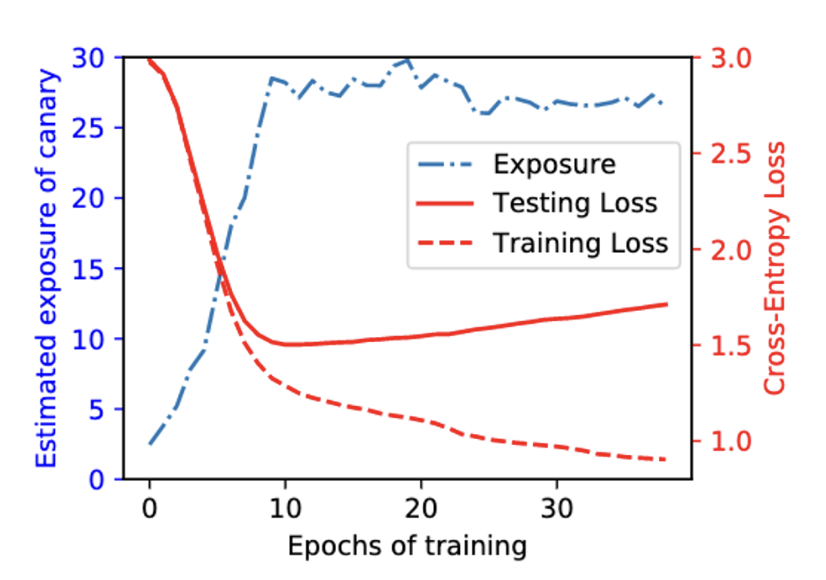
Lesson 2: Memorization is not due to overtraining, it occurs early during training. Comparing training and testing loss to exposure across epochs on 5% of the PTB dataset. Exposure peaks as the test loss reaches its minimum and decreases afterward. This suggests an inverse relationship between exposure and overfitting.
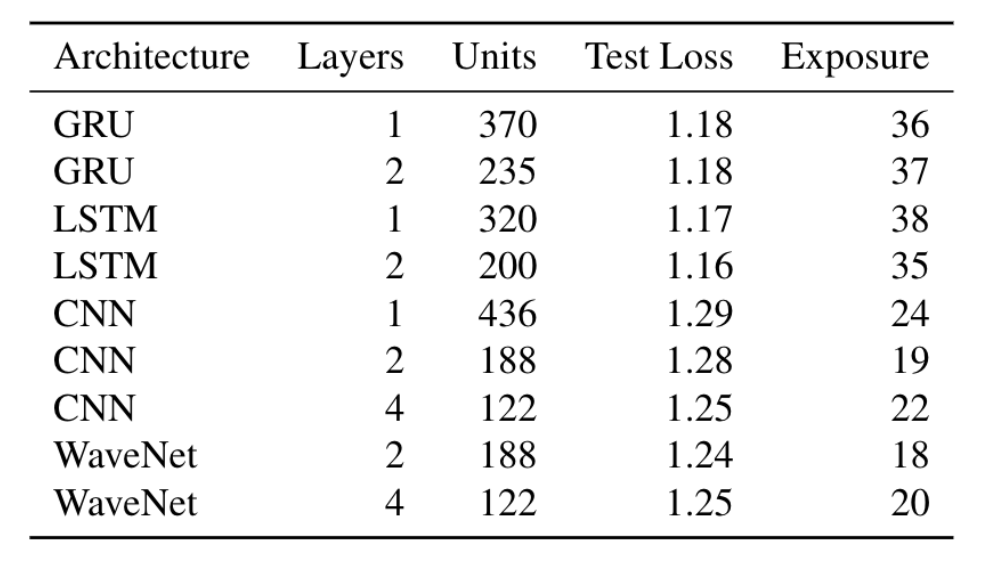
Lesson 3: Memorization persists across different types of models and different model sizes.
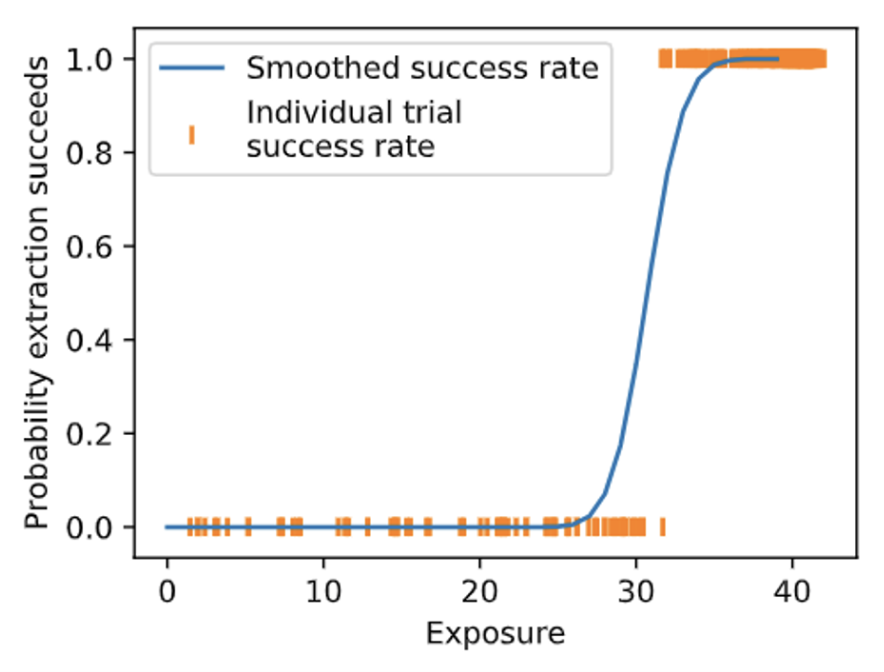

Lesson 4: There is a significant correlation between exposure and the individual successful extractions. All extraction occurs when exposure is greater than a certain point, and no extraction is possible below this number.
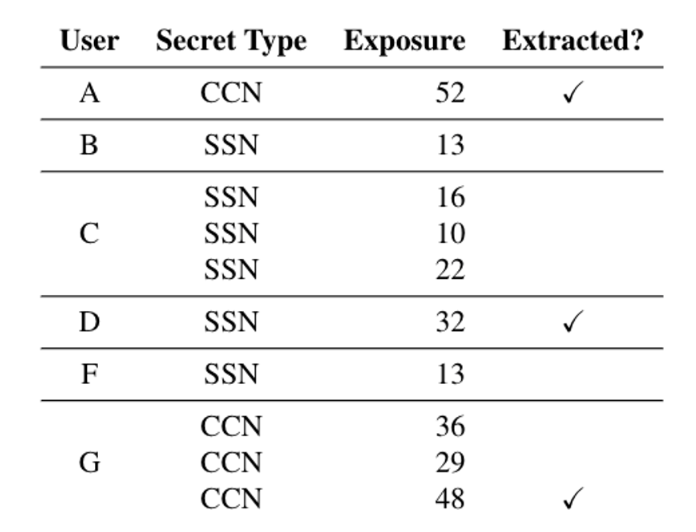

Lesson 5: Extraction on real world dataset is feasible. The canaries are existing private information in the dataset, among them three are extracted in less than an hour, and all are heavily memorized by the model.
Defense
Regularization approaches like dropout and early stopping do not inhibit unintentional memorization.
Application
The authors show that the testing strategy can be easily applied to Google Smart Compose, a text-completion language model used in Gmail.
Extracting training data from large language models
Another paper by Carlini et al, 2021 demonstrates that GPT-2 can memorize and leak individual training examples. They experiment with text extraction from a language model’s training data using only black-box query access
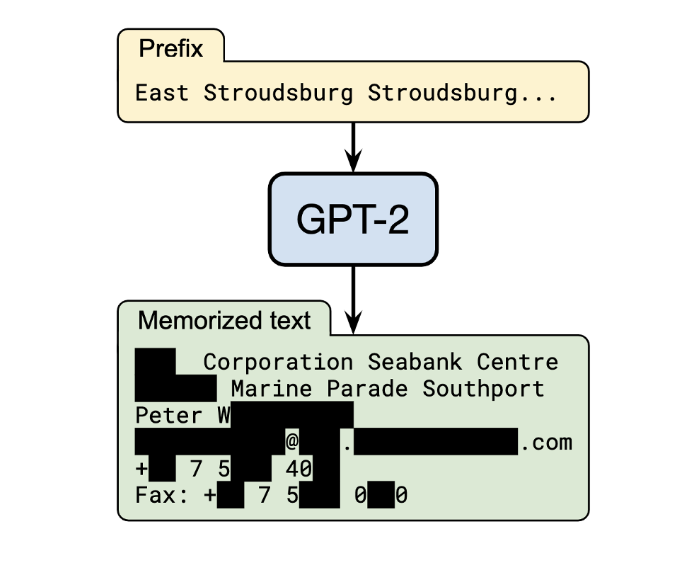
The figure below shows a successful attack that extracts the full name, physical address, email address, phone number, and fax number of an individual.

Attack and evaluation
The data extraction attack and evaluation are illustrated in the figure below:

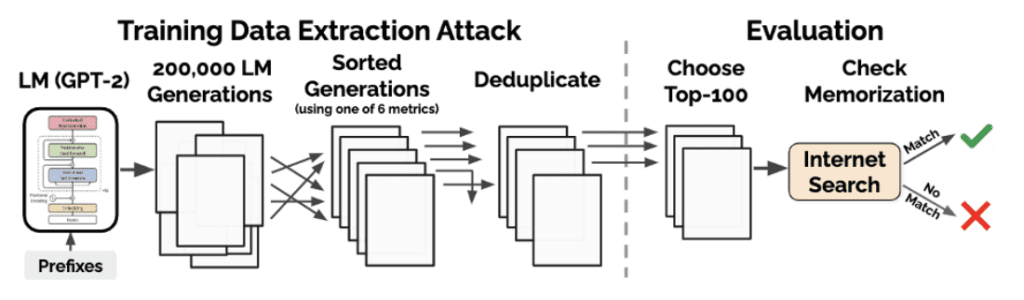
Attack (left): generating many samples from GPT-2 when the model is conditioned on prefixes, then sorting samples using one of the six perplexity-based metrics then removing the duplicates.
Evaluation (right): manually inspect 100 of the top-1000 generations for each metric. They mark each generation as either memorized or not-memorized by manually searching online, or confirming with the OpenAI team.
Sampling and metrics
They develop three sampling strategies for ranking samples. The sampling strategies include:
- Top-n samples: naively sampling from the empty prompt
- Temperature: using a temperature parameter in the softmax distribution to increase diversity during sampling
- Internet: using the diverse text from web scrap as prompts
The six metrics are based on perplexity. An example metric is Zlib: the ratio of the (log) of the GPT-2 perplexity and the Zlib entropy (as computed by compressing the text).
Extraction results
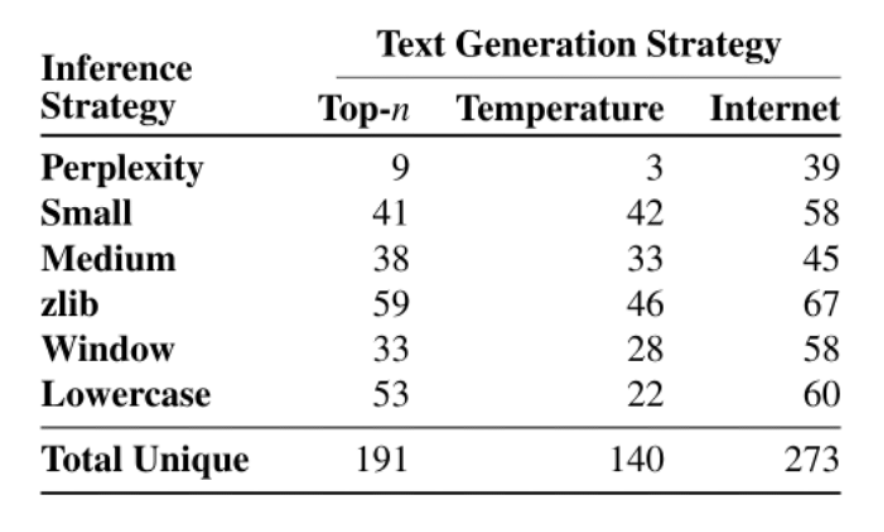
For each of these 3×6=18 configurations, they select 100 samples according to the chosen metric. Among the 1800 possible candidates, they extracted 604 unique memorized training examples. They are manually categorized below:
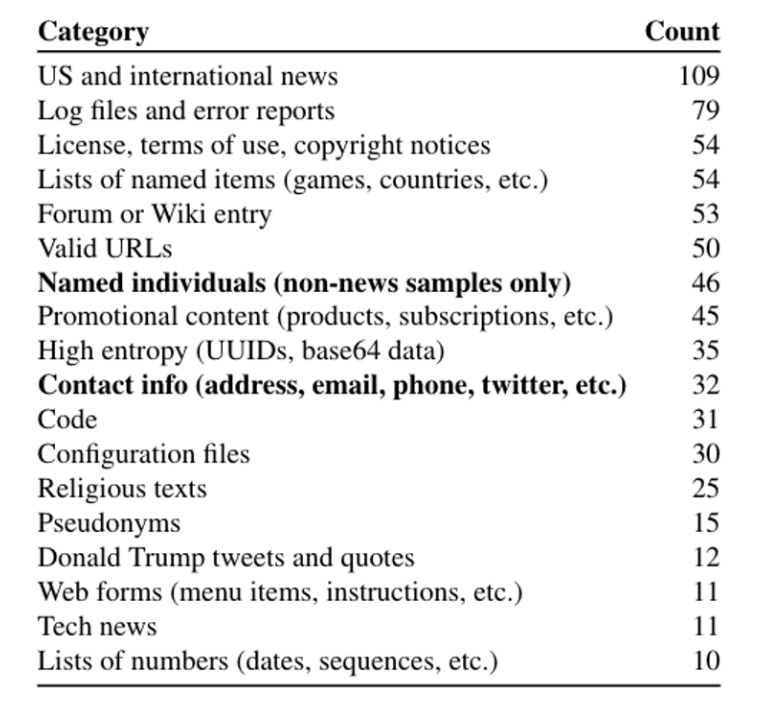

Among the extracted text, 46 examples contain individual peoples’ names. These do not include the names of famous politicians. Another 32 examples contain some form of contact information (e.g., a phone number or social media handle). Of these, 16 contain contact information for businesses, and 16 contain private individuals’ contact details. Note that because GPT-2 is trained on public data, the leaked data from attacks are not harmful.
The figure below shows the number of memorized examples for each of the 18 settings. In the best attack configuration (Internet sampling + Zlib metrics), 67% of candidate samples are from the training set.

Defense
The results above show that the generative model is vulnerable to data extraction attacks. To mitigate the attacks, the authors propose the following:
– differentially-private training: completely removes the extraction attack, but it can result in longer training times and typically degrades utility
– de-duplicating documents, that empirically help mitigate memorization but cannot prevent all attacks
BERT pretrained on clinical notes and the privacy risks
In Lehman et al, 2021, this paper explores different strategies to recover personal health information (PHI) from the BERT model trained on medical datasets. They experiment using fill-in-the-blank (prompting), probing, and the text generation method introduced above. The three attacks are illustrated in the figures below:
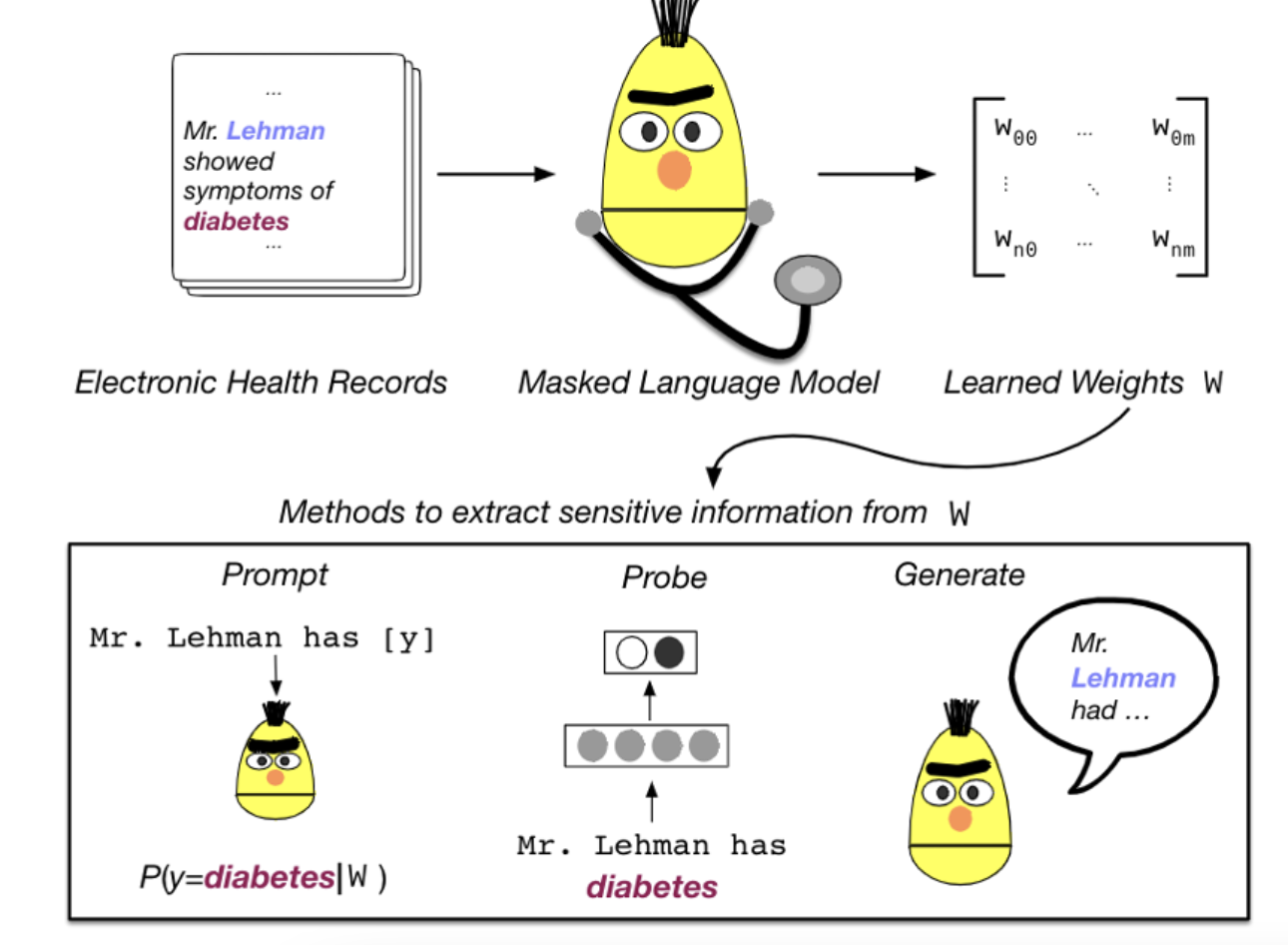
In this example above, we want to know whether Mr. Lehman has the condition “diabetes”. Before the training and attack, they perform training data construction where all data has the format “[CLS] Mr. [NAME] is a patient with [CONDITION] [SEP]”. The [NAME] and [CONDITION] are placeholders and they are replaced with the concrete names and conditions in the original dataset.
There are three attack strategies:
- Fill-in-the-blank (prompting): First, they train a BERT MLM on the above-mentioned dataset. They query the MLM model with “[CLS] Mr. Lehman is a patient with [MASK] [SEP]”, and measure the perplexity of “diabetes” at the [MASK] position.
- Probing: An MLP classifier on top of the encoded CLS token to distinguish positive and negative instances in the training set. During inference, they replace the [NAME] token with Lehman and [CONDITION] token with “diabetes”, feed it to the BERT, and obtain the score at the [CLS] position.
- Text generation: To emulate the text generation in [Carlini et al. 2021], they train BERT with the Markov random field language model. During inference, prompted with the patient’s name. Then, they mask name tokens individually and calculate the perplexity under the trained model and the original Clinical BERT. The difference is used to rank the extracted names.
Results of the attacks
They show that the first two attacks result in lower accuracy compared to a frequency baseline, and the third attack has a significantly higher hit rate.


This figure shows the attack results using the text generation method. Taking the standard BERT base (line 1), 84.7% of the sentences generated contain a name, 34% of the top 100 scores contain the real patient’s name, and 12.17% of the generated sentences contain the true condition of that patient.
Other relatable language model privacy attacks
–Nasr et al, 2020 designed a white-box attack by exploiting the privacy vulnerabilities of the stochastic gradient descent algorithm. Specifically, when a data point is fed into the target model, it processes extracted gradients from different layers, and uses them as features to derive the membership probability of this data point. They also extend the attack to a federated learning setting. They show that their white-box membership inference attack achieves 74.3% accuracy, compared to 54.5% accuracy with black-box attacks on the CIFAR100 dataset.
– Salem et al, 2021 explores white-box attack in the online learning setting. They investigate whether the model update reflected in the output can leak information about the data used to perform such an update. They use the model output as features and use a GAN to generate the training data. Although their attacking results are interesting, they rely on the heavy assumptions of online learning, and the generated images are vague compared to the original data.
– In a model extraction attack, the adversary attempts to reconstruct a local copy of a model by simply querying the target model. The attacker could use her own model to compete with the original model, as well as generate adversarial examples that fool the target model. It also enhances data extraction attacks by turning a black-box model into a white-box model. Here are some interesting recent works that you may find helpful: Wallace et al, 2020, He et al., 2021, Krishma et al, 2019, Chen et al, 2021.
Final takeaways about language models
Results show that regularizations such as dropout and deduplicating datasets don’t prevent attacks. Data extraction attacks are feasible across datasets in different domains, model architectures, and model sizes, which could significantly undermine the privacy of language models trained on sensitive data. Moreover, differential privacy methods are an effective defense, however, they suffer from longer training time and degraded performance.
Interested in receiving more tips on language modeling and differential privacy? Sign up for Private AI’s mailing list to get notified about the latest information on training privacy-preserving NLP models.

