

The new Tensorflow Lite XNNPACK delegate enables best in-class performance on x86 and ARM CPUs — over 10x faster than the default Tensorflow Lite backend in some cases. In this post I will be reviewing installation, optimization, and benchmarks of the package.
Tensorflow Lite is one of my favourite software packages. It enables easy and fast deployment on a range of hardware and now comes with a wide range of delegates to accelerate inference — GPU, Core ML and Hexagon, to name a few.
One drawback of Tensorflow Lite however is that it’s been designed with mobile applications in mind, and therefore isn’t optimised for Intel & AMD x86 processors. Better x86 support is on the Tensorflow Lite development roadmap, but for now Tensorflow Lite mostly relies on converting ARM Neon instructions to SSE via the Neon_2_SSE bridge.
There is, however, a new Tensorflow Lite delegate for CPU-based floating-point computations, XNNPACK, that does feature x86 AVX and AVX-512 optimizations. In this post I’ll walk you through using XNNPACK and show some benchmarks.

Installing & Using XNNPACK
Instructions for using XNNPACK can be found here. Most notably, there’s now a build flag that will enable the XNNPACK delegate by default. This is handy, as until now it wasn’t possible to load Tensorflow Lite delegates in Python. The command to build Tensorflow from source would look like:
bazel build –define tflite_with_xnnpack=true \
//tensorflow/tools/pip_package:build_pip_package
The Tensorflow Lite benchmark tool also now has a flag to enable the XNNPACK delegate. For example, to profile on your x86 machine, first build the profiler tool:
bazel build -c opt –verbose_failures \
tensorflow/lite/tools/benchmark:benchmark_model
Then run the profiler with the following command:
bazel-bin/tensorflow/lite/tools/benchmark/benchmark_model \
–graph= –warmup_runs=50 –num_runs=1000 \
–enable_op_profiling=true –use_xnnpack=true
Optimizing for XNNPACK
It is important to ensure that models are suitable for XNNPACK, as it only supports a subset of all Tensorflow Lite operators. For example, the standard Keras implementations often use explicit padding layers and implement the top global pooling layer via the mean operator. When using the normal TFLite backend this only increases runtime by a few percentage points, but these operations aren’t supported by XNNPACK, resulting in considerable overhead — 30% in the case of MobileNet V2 with 8 threads(see below)!
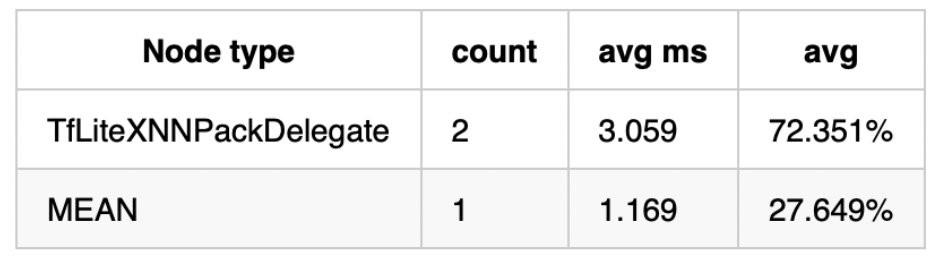
Padding is easily fixed by replacing the explicit padding layers with padding built into the convolution operations:
# Before x = layers.ZeroPadding2D(padding=((3, 3), (3, 3)), name='conv1_pad')(img_input) x = layers.Conv2D(64, 7, strides=2, use_bias=use_bias, name='conv1_conv', padding='valid')(x)# After x = layers.Conv2D(64, 7, strides=2, use_bias=use_bias, name='conv1_conv', padding='same')(img_input)
The global average pooling layer can be replaced by a average pooling layer with a large kernel:
# Before
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(classes, activation='softmax')(x)# After
# Use XNNPACK compatible average pooling
x = layers.AveragePooling2D(pool_size=(7, 7))(x)
# Implement the top dense layer as a convolution, so we don't need to remove spatial dims
x = layers.Conv2D(classes, kernel_size=1)(x)
x = layers.Softmax()(x)
Note that you will have to retrain the model. You can find fixed versions of these models in the repo accompanying this article here.
Benchmarks
ARM
Ok, so benchmarks! First I decided to test MobileNet V3 on my Galaxy S8:
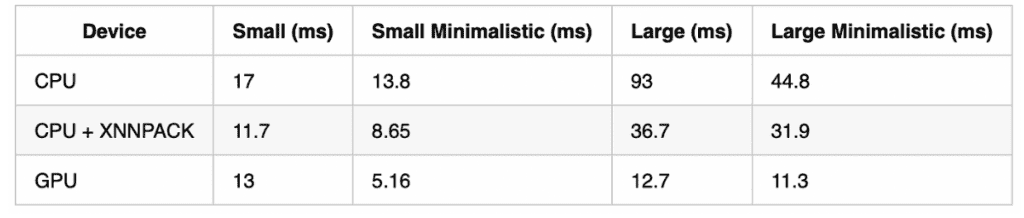
I tested using 1 thread over 1000 iterations, with 50 warm up iterations.
As you can see, XNNPACK offers excellent performance, on top of the standard Tensorflow Lite CPU backend. It’s worth noting that XNNPACK supports ARM Float 16 instructions included in newer ARMv8.2-A CPUs (e.g., A55), but unfortunately I don’t have one on hand. The GPU backend is still faster, especially for larger models. However, it requires OpenGL ES 3.1 or higher, which is only available on ~2/3 of all Android devices (see market share here.
x86
Now on to x86. I decided to compare against Intel’s OpenVino package using MobileNet V2 and ResNet50. For testing I used a Google Cloud N2 Cascade Lake instance, with 8 vCPUs. With 1 thread:
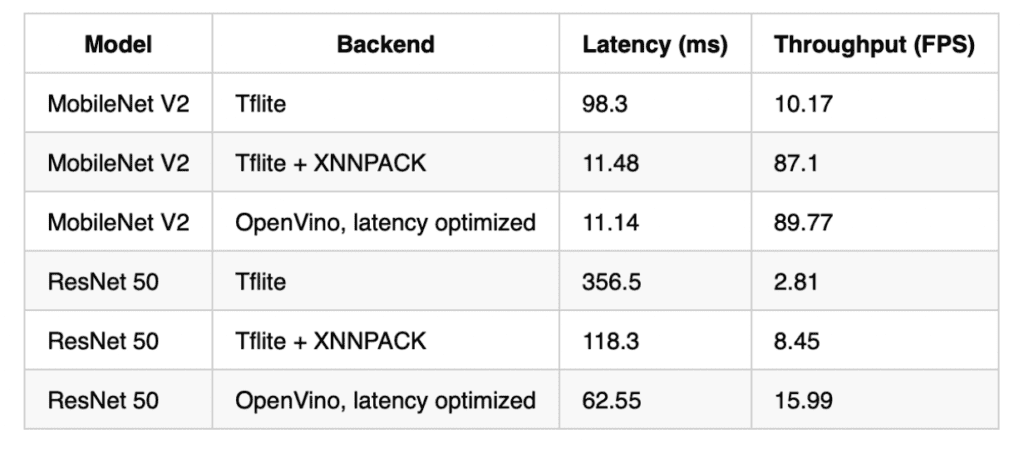
And 8 threads: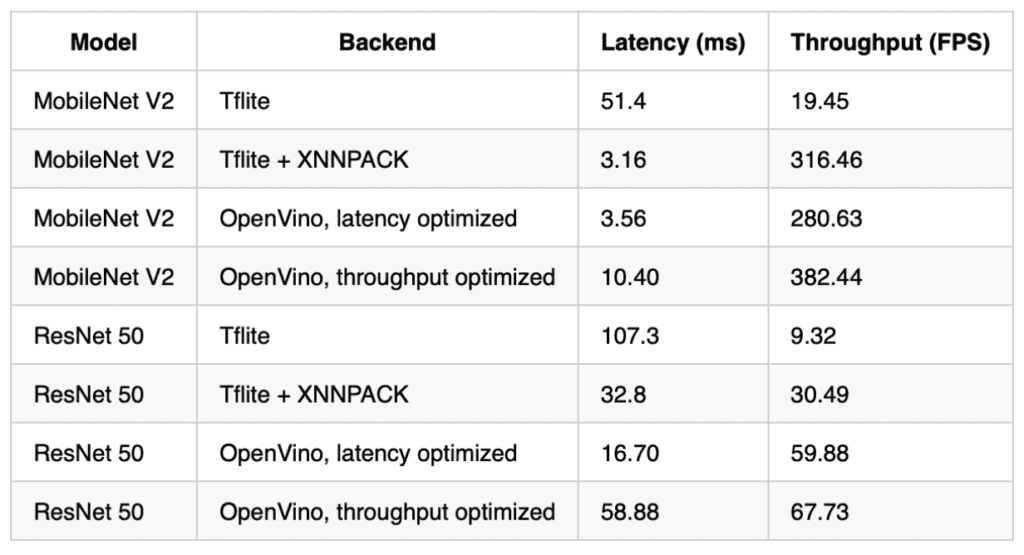
As you can see, Tensorflow Lite using the XNNPACK delegate performed admirably, in some cases over 10x faster than the default Tensorflow Lite backend. Performance approaches that of OpenVino for MobileNet V2, but falls short for ResNet 50. I don’t see this as a huge issue however, as depthwise convolution based architectures such as MobileNet V2 are far better suited for CPU deployment. XNNPACK also features better scaling over multiple CPU cores than the standard backend.
Note that the TFLite benchmark tool corresponds to OpenVINO’s latency mode, so it would be interesting to see what XNNPACK could deliver if configured for throughput.
Tensorflow Lite can now offer great x86 performance via the new XNNPACK delegate, outperforming Intel’s OpenVino package in some cases
The main drawback of XNNPACK is that it is designed for floating point computation only. 8-bit model quantization can easily result in a >2x performance increase, with an even higher increase when deployed on the new Intel Cascade Lake CPUs which support AVX-512 VNNI instructions. Support for 8-bit quantization on x86 is on the Tensorflow Lite roadmap, perhaps even in the next release.
Similarly, for mobile deployments, XNNPACK outperforms the Tensorflow default backend. Whilst the GPU delegate is still faster than XNNPACK, XNNPACK is useful on devices that don’t support GPU computation.
XNNPACKsimplifies the deployment process by allowing one to stay within the Tensorflow Lite ecosystem
It is now possible to convert a model once and deploy to multiple platforms, reducing the number of different software packages required. It’s also worth noting that AMD processors are becoming less of a rarity, and OpenVino is an Intel product. I tried to test on a Google Cloud N2D EYPC instance, but unfortunately, I couldn’t get my quota increased.
The code to reproduce these benchmarks is located here and here.
Follow Private AI for the latest in machine learning on LinkedIn, Twitter, and Youtube

