

Large Language Models (LLMs) like Azure’s OpenAI service have become pivotal technology, enabling machines to understand and generate human-like replies to questions posed in a chat format. For organizations looking to augment those models with domain specific knowledge or for traditional ML applications such as sentiment analysis, fine tuning has emerged as an approach to perform specialized tasks with a higher degree of accuracy and relevance. However, a critical concern emerges when fine-tuning involves data containing Personally Identifiable Information (PII). This blog embarks on a journey to explore why generative AI entails more risk from a privacy perspective than previous ML techniques and demonstrates how redacting PII before fine-tuning can mitigate this problem.
Section 1: Unraveling the Fine-Tuning of LLMs
Fine-tuning involves adapting pre-trained LLMs to a specific domain or task by training them further on a particular dataset, enhancing their utility and accuracy in specialized applications. This process is crucial, especially in domains that require specialized knowledge, such as technology, finance, or healthcare. Here, we dive deeper into the stark difference between generic LLM responses and those from a fine-tuned model.
Consider an open dataset from Nvidia, which contains detailed information and specifications about various graphics processing units (GPUs). When developers or data scientists query an LLM about specific GPU attributes or features, the responses from an un-fine-tuned model may lack accuracy and specific insights present in the dataset.
Code Example 1: Querying an Un-Fine-Tuned LLM:

Want to see the code? Try it here
In this instance, the un-fine-tuned LLM provides an answer that seems plausible at first glance. However, it is not accurate according to the specific dataset. This is an example of a model hallucination, where the model generates a response that sounds reasonable but is not substantiated by the training data.
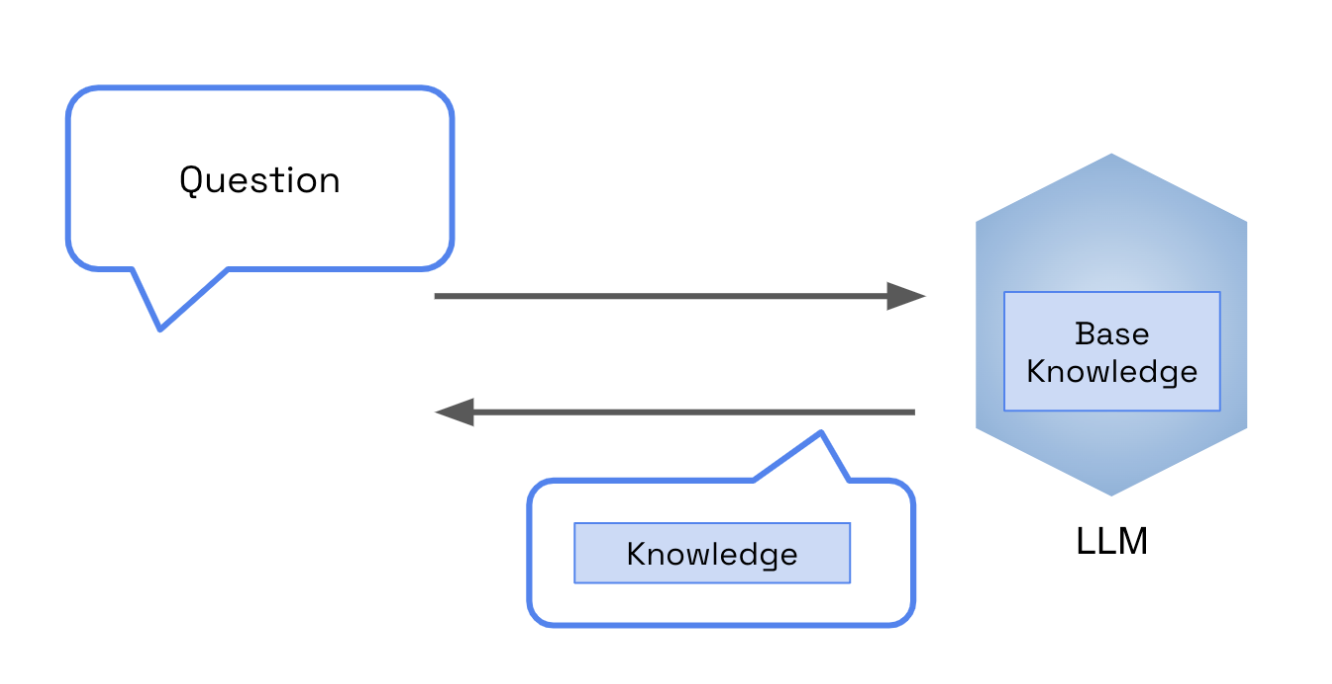
The reason for this incorrect response is because the base knowledge of the LLM lacks insight into the domain. As a result, it is forced to leverage the information it does have to try and answer the request.
Code Example 2: Interaction with a Fine-Tuned LLM
Embarking further, let’s delve into an interaction with an LLM that has been fine-tuned using a domain-specific dataset, in this case, an open dataset from Nvidia. Fine tuning involves augmenting the knowledge of an LLM with additional data to provide it with domain expertise needed to answer new kinds of questions. For example, without additional information provided in a prompt, ChatGPT wouldn’t know the details of an organization’s internal HR policies or answer questions around proprietary and confidential information. In our example, the enriched model is now capable of providing detailed and accurate responses to queries related to Nvidia GPUs.

Want to see the code? Try it here
This response, which aligns with the specifics of the Nvidia dataset, underscores the value of fine-tuning. It provides a precise and accurate answer that reflects the specialized knowledge contained within the training data. Because the model was fine tuned with domain information, it is now able to answer the question appropriately.

However, the precision and specialization that come with fine-tuning also present potential pitfalls, especially when it comes to handling sensitive or private information. For instance, if the dataset used for fine-tuning contains PII or other sensitive details, the model might inadvertently expose this data in its responses. Let’s take a look at an example.
While the Nvidia dataset being used contains publicly available data, let’s assume that information about specific people, or organizations are in fact private. For example, imagine an organization was developing a top secret AI system that could generate and sing songs.
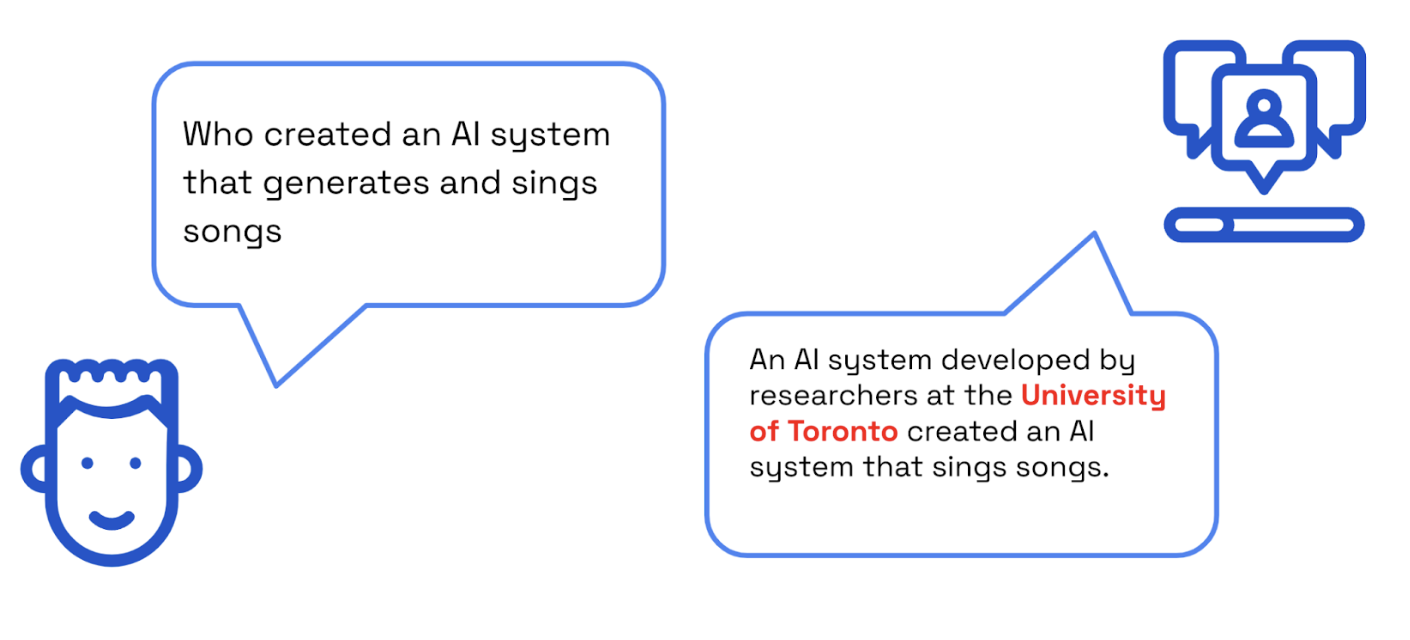
Want to see the code? Try it here
In the accompanying graphic, we see a scenario that underscores the potential risks involved when privacy measures are overlooked. The illustration shows a chatbot, initially designed to interact seamlessly with users, responding to a query about generating and singing songs. However, instead of a generic response, the chatbot leaks sensitive information, revealing details about a specific organization’s confidential data. This was the case with ScatterLab who trained a chatbot on the personal conversations of their users and inadvertently exposed their private data.
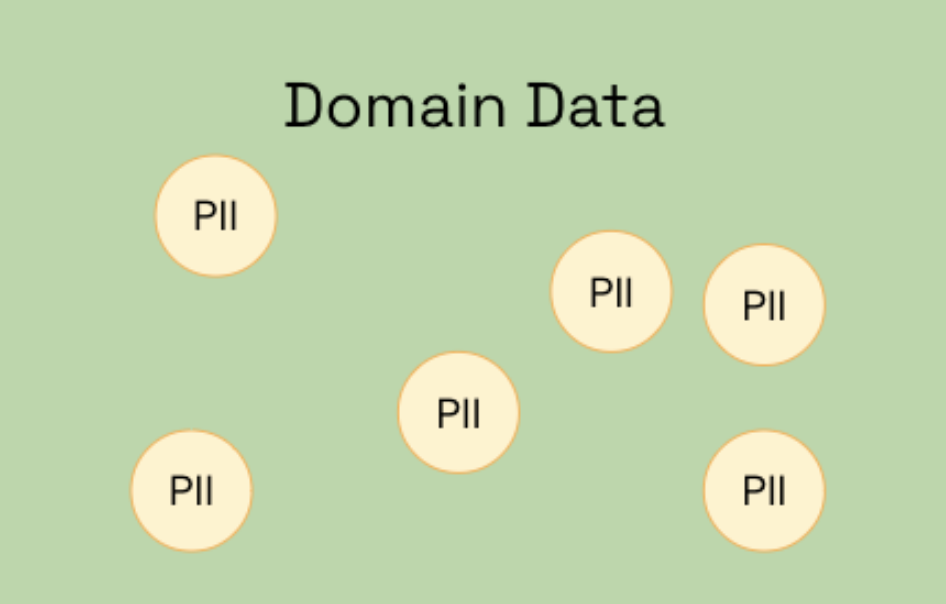
Data leaks like this occur because if one inspects the training data more closely, all sorts of PII are observed such as names, locations, dates and other sensitive information. When LLMs such as Azure OpenAI are trained on this data, they not only learn the domain expertise, but also information about private data too.
This serves as a stark reminder of the unintended consequences of inadequate data privacy measures. In this instance, the confidential details of the organization’s project were not redacted from the dataset, leading to an AI mishap that not only breaches privacy but also potentially compromises the organization’s competitive advantage. The domino effect that can result from a single oversight in data privacy, highlighting the critical need for stringent data sanitization practices in every step of AI development.
Section 2: Redaction as a Means of Preserving Privacy in Training Data
In the previous section, we saw that fine-tuning LLMs with sensitive but powerful data risks exposing that data. That’s where ‘redaction’ comes in. Redaction is a straightforward yet effective method for protecting privacy. It involves deliberately altering or removing sensitive information from datasets before they’re used for training. This way, personal or confidential details aren’t just shielded from public view; they’re kept entirely out of the AI’s learning process.

Redaction, a tried and tested technique long utilized in the legal space, is rapidly becoming a crucial necessity in the field of AI. It’s worth noting that the concept of redaction is easily grasped by non-technical data custodians, such as call centre managers at banks, in contrast to more complex methodologies like differential privacy. By systematically obscuring personal identifiers or sensitive information, redaction ensures that the consequential essence of the data remains intact for model training, while the privacy of individuals is uncompromised.
Code Example 3: Querying a LLM Fine-Tuned with Redacted Data:

Want to see the code? Try it here
The application of redaction extends beyond just removing text or data points; it’s an intricate process involving various techniques such as data masking, tokenization, and pseudonymization, each catering to different needs and levels of privacy preservation. This strategic alteration allows AI to learn patterns and make decisions based on data trends rather than individual profiles.
While these methods contribute to protecting sensitive information, the clear format of the redaction markers mean it’s also easy to re-identify PII when necessary. For users with appropriate permissions, data can be “re-hydrated”. For example, one could discern what ‘organization_1’ represents, when required for legitimate purposes.
RAG, Prompt Engineering and Other Approaches
While this discussion primarily revolves around fine-tuning as a means to enhance language models’ proficiency in specific domains, it’s important to acknowledge the existence of other effective strategies. One notable method is the Retrieval-Augmented Generation (RAG) approach, which combines the retrieval of documents from a vast corpus and the generation capabilities of large language models to produce more informed responses. Techniques like RAG can significantly improve a model’s ability to handle queries without the need for extensive retraining or fine-tuning. However, irrespective of the method employed, the critical principle of data privacy remains constant. Every approach requires some level of interaction with data, and it’s our responsibility to ensure that this data is handled with the utmost regard for privacy.
Conclusion
As we traverse the path of utilizing LLMs, prioritizing privacy by redacting PII during fine-tuning becomes imperative. The intersection of utility and privacy in AI systems is a continually evolving landscape, and your insights could pave the way for new breakthroughs. We invite you to share your thoughts and experiences in managing privacy during LLM fine-tuning, contributing to the responsible advancement of AI technology.

