

Mitigate ChatGPT Privacy Concerns with PrivateGPT Headless

The Problem:
There's a wave of ChatGPT-powered applications, but enterprises don’t want their data sent to ChatGPT
Generative AI, such as OpenAI’s ChatGPT, has enabled a range of new applications. In particular, many ML-powered applications such as summarisation and chatbots are moving to ChatGPT.
The problem is that most enterprises have blocked ChatGPT internally and aren’t OK with their data being sent out of their systems to OpenAI. And for good reason too, ChatGPT was temporarily banned in Italy and has already had its first data leak, which exposed personal information including some credit card details.
Enterprises also don’t want their data retained for model improvement or performance monitoring. This is because these systems can learn and regurgitate PII that was included in the training data, like this Korean lovebot started doing, leading to the unintentional disclosure of personal information.
Enter PrivateGPT:
Easily identify and remove 50+ types of PII inside your application before sending it through to ChatGPT
With the help of PrivateGPT, developers can easily scrub out any personal information that would pose a privacy risk, and unlock deals blocked by companies not wanting to use ChatGPT.
With PrivateGPT Headless you can:
- Prevent Personally Identifiable Information (PII) from being sent to a third-party like OpenAI
- Reap the benefits of LLMs while maintaining GDPR and CPRA compliance, among other regulations
- Avoid data leaks by creating de-identified embeddings
- Show DPOs and CISOs how much and what kinds of PII are passing through your application
- Help reduce bias in ChatGPT by removing entities such as religion, physical location, and more
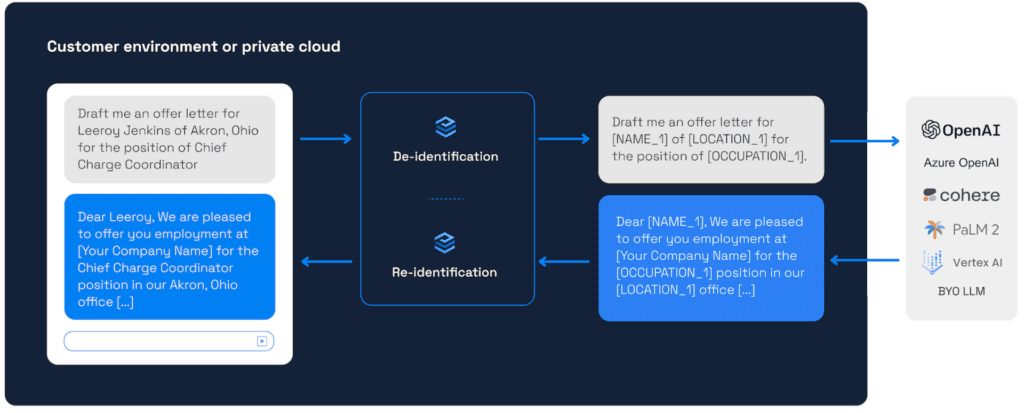
How it Works
It’s as simple as a few lines of code around each OpenAI call. Data is de-identified and then re-identified by a container running in your or your customer’s premises. No data is ever shared with Private AI.
import openai
from privateai import PrivateGPT
MODEL = "gpt-3.5-turbo"
messages = [{"role": "system", "content": "You are an email answering assistant"},
{"role": "user", "content": "Invite Tom Hanks for an interview on April 19th"}]
privategpt_output = PrivateGPT.deidentify(messages, MODEL)
response_deidentified = openai.ChatCompletion.create(model=MODEL, messages=privategpt_output.deidentified, temperature=0)
response = PrivateGPT.reidentify(response_deidentified, privategpt_output)
Test it yourself for free with the PrivateGPT UI version, or contact us to go Headless today:
Why Private AI
Deploys as a Docker container - no data is ever shared with us
50+ entity types covering all major regulations like GDPR, HIPAA & PCI DSS
Runs in real-time - the user won’t notice it’s there
Built for scale. A single container can service thousands of requests/sec
Advanced re-identification to put PII back into the response from OpenAI
Works with any LLM service, such as Anthropic and Cohere
We understand the significance of safeguarding the sensitive information of our customers. With Private AI, we can build our platform for automating go-to-market functions on a bedrock of trust and integrity, while proving to our stakeholders that using valuable data while still maintaining privacy is possible.
